


Seit April ist Diego Areces neuer CEO bei Baumueller-Nuermont, das nordamerikanischen Tochterunternehmen der Baumüller-Gruppe.
Bild: Baumüller Nürnberg GmbH



Seit April ist Diego Areces neuer CEO bei Baumueller-Nuermont, das nordamerikanischen Tochterunternehmen der Baumüller-Gruppe.
Hexagons Manufacturing Intelligence Division hat eine strategische Partnerschaft mit Microsoft bekannt gegeben.

Microsoft Deutschland und IFM Electronic haben auf der Hannover Messe eine Partnerschaft vereinbart.
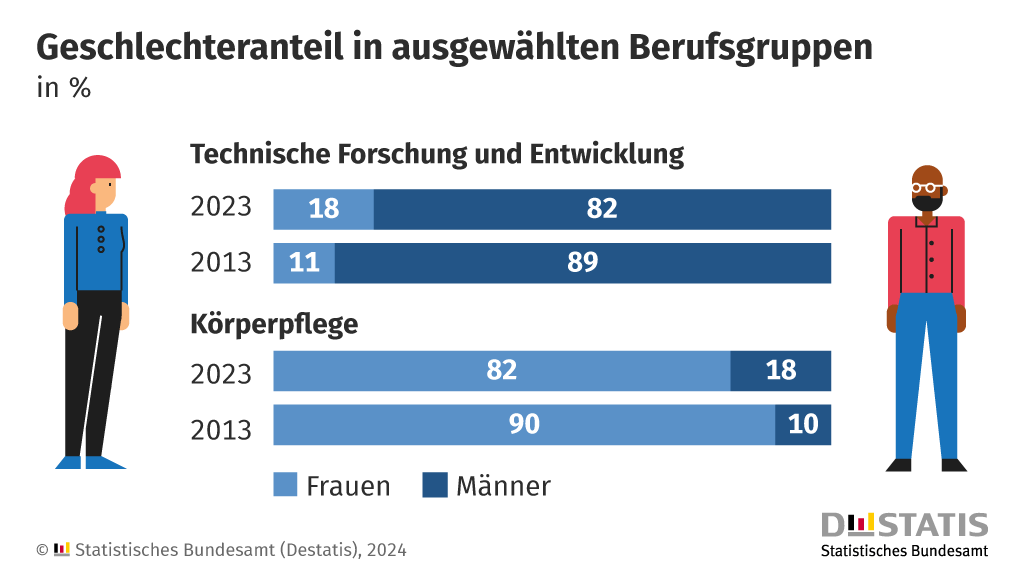
Frauen sind in der IT oder Forschung und Entwicklung nach wie vor unterrepräsentiert, Männer in Körperpflegeberufen oder im Verkauf von Lebensmitteln. Doch das ändert sich zunehmend. So ist der Frauenanteil in der technischen Forschung und Entwicklung im Jahr 2023 auf 18% gestiegen.

Phoenix Contact erweitert sein Netzwerkportfolio um WLAN-Client-Module gemäß dem Standard WiFi6 (IEEE 802.11ax).

Die modularen Emotron-Frequenzumrichter von CG Drives & Automation sind auf den Betrieb vollelektrischer und hybridelektrischer Systeme ausgelegt.
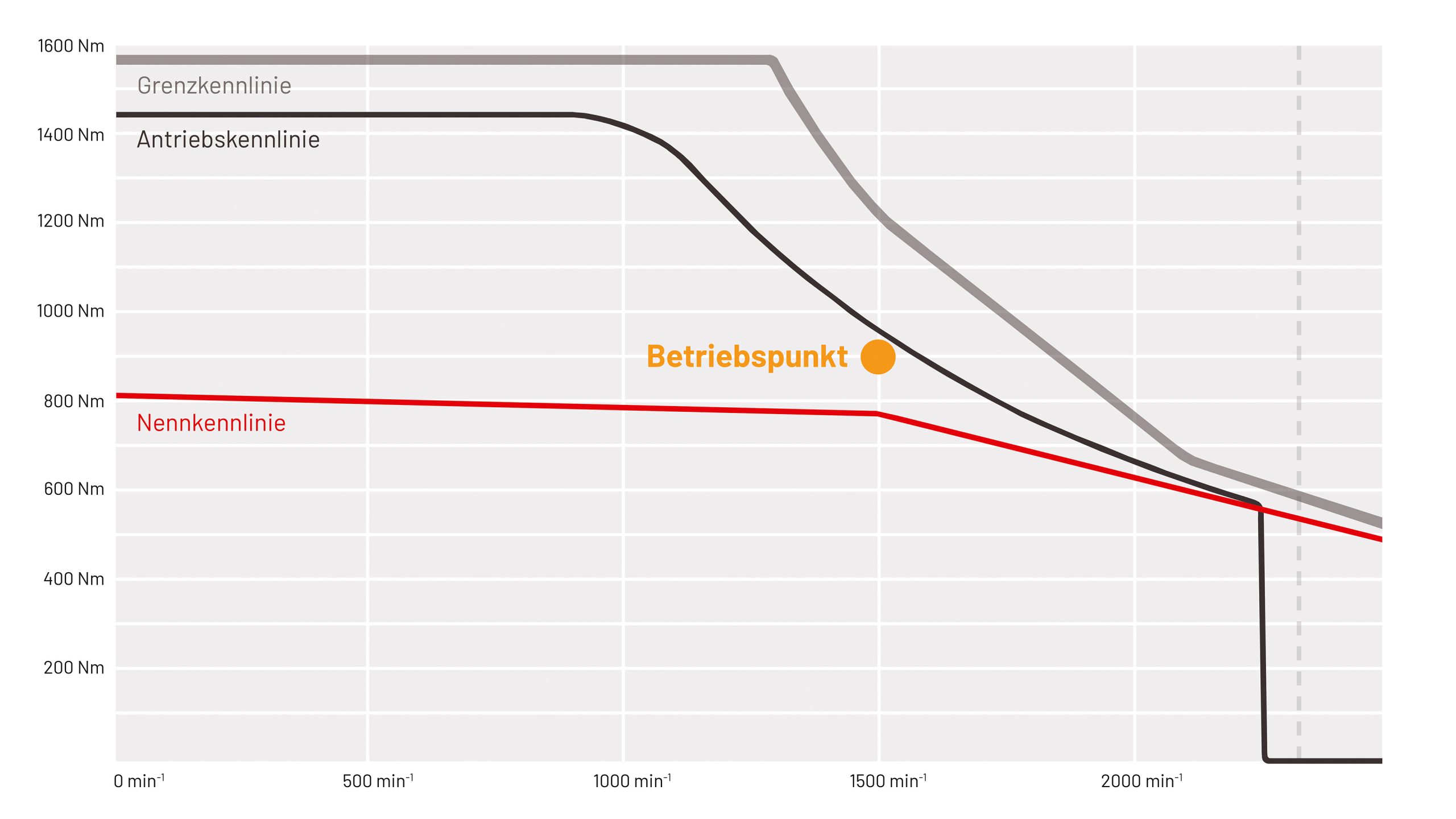
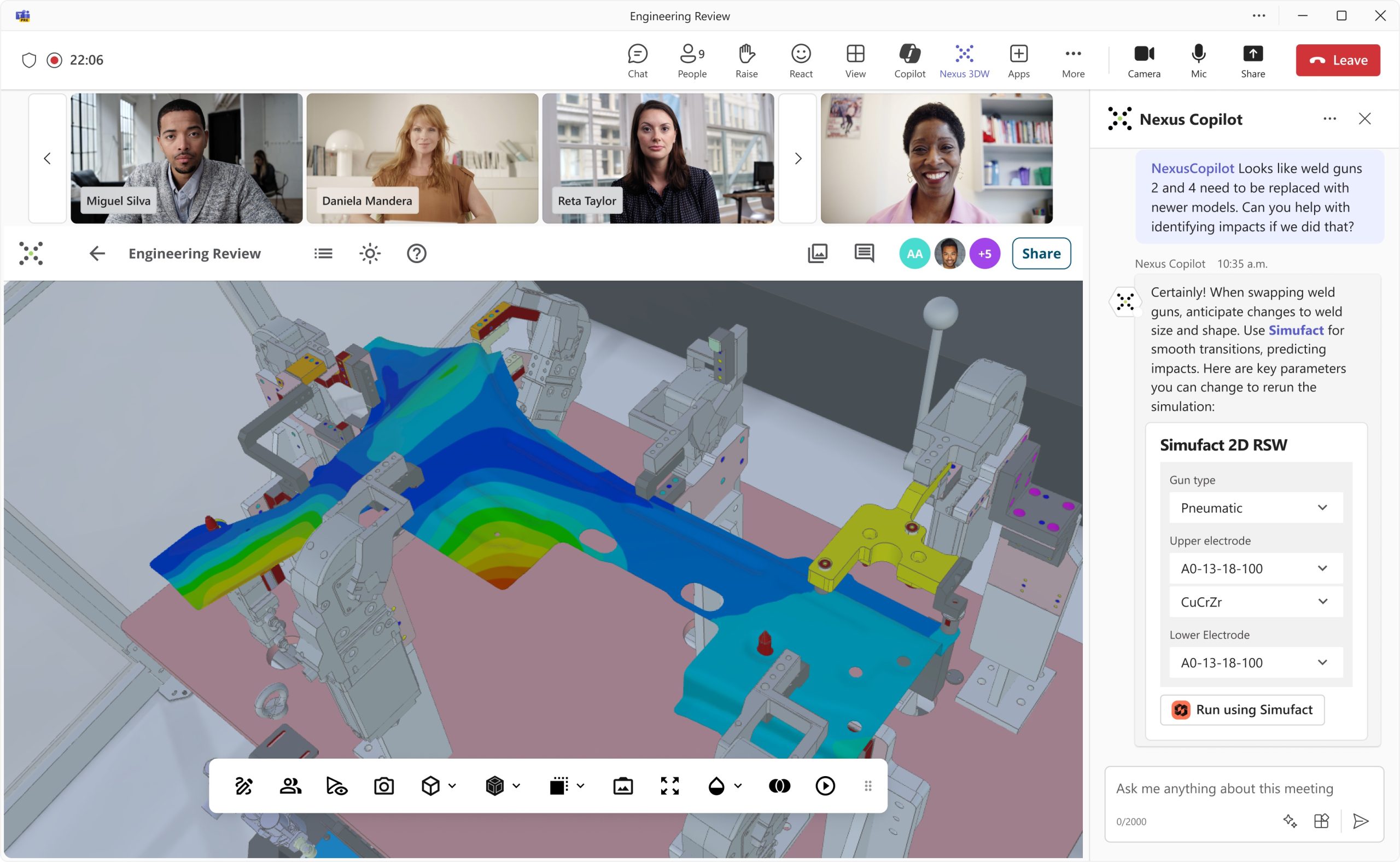
Um die Auslegung von Antriebssystemen zu erleichtern, hat Baumüller das Inbetriebnahme-Tool ProDrive um eine Antriebskennlinien-Analyse erweitert, die bei der Neuentwicklung von Maschinen sowie im Service genutzt werden kann.

Die Kostal-Umrichter Inveor MPP und MPM sind nun serienmäßig mit der Funktion Vibration Monitoring ausgestattet, die vor allem in Pumpenapplikationen ihren Mehrwert ausspielen soll.

Bestellen Sie jetzt die Ausgabe 3 2024 des SPS-MAGAZINs. Und erfahren Sie alles zum Thema Automatisierungstechnik.

Die Fortric TA3 von Meilhaus Electronic ist eine Plugin-Wärmebildkamera für Smartphones.

SEW-Eurodrive hat sein 48V-Portfolio um ein Verstellantriebssystem auf Schrittmotorbasis erweitert, das die Umsetzung von Verstellachsen mit Open-Loop- oder Closed-Loop-Regelung erlaubt.

Der integrierte Schrittmotorantrieb ASI8100 von Beckhoff kombiniert Schrittmotor, Endstufe und Feldbusanschluss in platzsparender Bauform bis 48VDC.

ABB hat den neuen platzsparenden FI/LS-Schalter (RCBO) DS201 UL auf den Markt gebracht.

Der neue Embedded-PC DRPC-124-EHL von Compmall basiert auf der J-Reihe von Intel.

Das Miniaturpositioniersystem XYZ-Phi-Delta von Steinmeyer Mechatronik besteht aus einem Tripod (MP200-3) und einem XY-Kreuztisch (KDT235) – beide mit Durchlichtöffnung – und soll so die Vorteile parallelkinematischer und gestapelter Systeme vereinen.

Auf der Hannover Messe war Innomotics das erste Mal als eigenständiges Unternehmen vertreten.

Mit der Software Eplan Cable proD soll es ab September möglich sein, vorkonfektionierte Kabel vom Schrank zur Maschine, mit passender Länge und Kabelweg im 3D-Modell zu definieren.

Die neuen UT-Tüllen von Icotek eignen sich für die einfache und effiziente Einführung von Leitungen mit und ohne Stecker in Gehäuse.

Der integrierte Motion Controller 22xx…BX4 IMC von Faulhaber verfügt über sehr kompakte Abmessungen.

Nanotec erweitert seine Produktpalette um den Hightorque-Schrittmotor ASA5618.

Die Linearmotoren und Profilschienenführungen der Gantry-Systeme von Hiwin sorgen zusammen mit hochauflösenden Wegmess-Systemen für eine exakte Positionierung.

Die neue Steuerung CP 931 von Sigmatek verfügt über einen leistungsstarken Intel-Prozessor vom Typ Core i3 Tiger Lake.

Das CrossBoard von Wöhner erfährt ein Upgrade und verschiebt die Grenze von 160 auf nunmehr 800A Bemessungsstrom.

Wenn sich Anlagenbauer in der Vergangenheit auf die Suche nach einem doppelwandigen und sehr breiten Outdoor-Gehäuse gemacht haben, waren in der Regel Sonderanfertigungen das Mittel der Wahl.

Mit der Variante GPA der Lineareinheit Modul 160/15 von IEF-Werner lassen sich zwei Flächenportale innerhalb des gleichen Arbeitsraums betreiben.

Weiss liefert sein direkt angetriebenes Lineartransfersystem LS One als Komplettpaket: vorkonfiguriert, vorprogrammiert und inklusive passendem Gestell sowie entsprechenden Aufbauplatten.

Siemens kündigt auf der Hannover Messe eine neue SPS-Generation an, die ab Winter verfügbar sein soll.



Mit der App Industrial News Arena erfahren Sie wichtige Nachrichten aus Ihrer Branche sofort. Lesen Sie zu jeder Zeit, welche Branchen-Themen die Community aus Ihrem Interessengebiet bewegen. In wenigen Augenblicken gewinnen Sie Tag für Tag schnell den Überblick über alle relevanten Ereignisse aus der Automatisierung, industriellen Bildverarbeitung, Gebäudetechnik, industriellen IT, Robotik und Schaltschrankbau. Die einfache Navigation macht das Lesen von Nachrichten zu einem neuen Erlebnis.
Die kostenlose App können Sie hier downloaden:
http://app.industrialnewsarena.de

Time-Sensitive Networking – ZEIT ZUM HANDELN! 2020 ist das 20. Jubiläum der CC-Link Partner Association. Erfahren Sie, wie CC-Link IE TSN Ihr Unternehmen untestützen kann, sich auf die Automatisierungsaufgaben der nächsten 20 Jahre vorzubereiten.

Wir stellen uns diesen Herausforderungen, denn wir sind gut gerüstet. Neben qualitativ hochwertigen Produkten, die das ganze Spektrum von Low- und Middle- bis High- End-Automatisierungsprodukten und -Lösungen abdecken, sind unsere Spezialisten visionär und arbeiten in einem weltumspannenden Netzwerk aus Niederlassungen, Servicestationen, Systempartnern und Entwicklern.


